


EYとは、アーンスト・アンド・ヤング・グローバル・リミテッドのグローバルネットワークであり、単体、もしくは複数のメンバーファームを指し、各メンバーファームは法的に独立した組織です。アーンスト・アンド・ヤング・グローバル・リミテッドは、英国の保証有限責任会社であり、顧客サービスは提供していません。

半導体の微細化技術はムーアの法則に従って進化してきましたが、2010年ころを境に微細化ペースの鈍化が顕著になっています。この技術の制約と、その制約を乗り越えるコンピューティング技術の進化が昨今のデータセンター需要拡大をけん引しています。本稿ではそれらの関係性を明らかにします。
本稿の執筆者
EYストラテジー・アンド・コンサルティング株式会社 ストラテジー事業部 TCF Lead Advisory 小室 英雄
TMT業界、金融業界、不動産業界を中心にプレM&AフェーズからM&Aの実行、海外PMIハンズオン支援までLifecycle支援に強みを有する。EYストラテジー・アンド・コンサルティング株式会社パートナー。
要点
- 半導体の微細化鈍化に伴い、回路の高集積化による高性能化が限界に。複数のチップの組み合わせで性能を高めると必要なチップ数が増え、コンピュータシステムが大型化
- 放熱量の増大に伴い冷却システムの高度化も進展
- 1つのチップの性能向上の鈍化を補うため並列演算が導入され出した。初期の並列プログラミングの難しさをディープラーニングが打開し、生成AIが並列演算の一般利用を加速
- 半導体技術の制約によるコンピュータシステムの大型化と、生成AIなどコンピューティング需要の拡大の受け皿としてデータセンターの需要は構造的に拡大
Ⅰ はじめに
近年、データセンターの需要が拡大しています。この現象は日本国内にとどまらず、米国や欧州など世界中で起こっており、新規データセンターの建設ラッシュとなっています。
本稿の目的は、主にデータセンター関連のビジネスに携わる方々に対し、この需要の拡大が一過性のAIブームにとどまらない構造的なものである可能性をお示しすることです。構造的な需要拡大の背景には、半導体の微細化技術の鈍化(第Ⅱ章)と並列コンピューティング技術の進化(第Ⅲ章)、これらを土台とした生成AIによる高性能コンピューティングの民主化(第Ⅳ章)があります。なお、文中の意見にわたる部分は筆者の私見であることをあらかじめ申し添えます。
前回の記事はこちらからご覧いただけます。
Ⅱ 半導体の微細化技術の鈍化
第Ⅱ章では、半導体の微細化技術の鈍化が半導体チップ面積の大型化、その結果コンピューターシステムの大型化につながることを説明します。
半導体の微細化技術は、ムーアの法則と言われる経験則に従って長らく技術革新が進められてきました。ムーアの法則では、18カ月から24カ月ごとに半導体のトランジスタ回路の集積度が2倍に高まると予想されていました。ゴードン・ムーア氏がこの法則を提唱した1960年代後半から2010年ころまでの約50年間にわたって、この法則は半導体の技術開発の指標として機能し、半導体の性能は向上してきました。微細化世代が1世代進むと、同じトランジスタ回路数であれば半導体チップ面積は約半分に、その製造コストも約半分になり、一方で消費電力量が低下し動作周波数が引き上げられて演算性能は高まります。すなわち微細化は、小型化と高性能化と低コスト化を同時に実現する原動力だったと言えます。
<図1>は半導体プロセッサの性能向上トレンドを示しています。横軸は年単位の時間軸、縦軸は対数軸でトランジスタ回路数や1スレッド当たりの整数演算回数、動作周波数、消費電力量、ロジック演算コア数を表しています。
半導体の微細化技術の進化により半導体プロセッサに搭載されるトランジスタ回路数は1970年代の数千個から現在では100億個へと指数関数的に増加しています。その増加に合わせて1スレッド当たりの整数演算回数も上昇し、半導体プロセッサの演算性能は飛躍的に向上してきました。
しかし、2005年ころからこの関係性が崩れ始めています。消費電力の増加に伴う発熱量の増加によってトランジスタ回路が熱暴走し、機能しなくなることが主な原因です。発熱量抑制のために動作周波数を高められなくなり、結果的に1スレッド当たりの整数演算回数の向上も鈍化しました。<図1>では緑のFrequencyや赤のTypical Powerが横ばいとなり、青のSingle Thread Performanceの傾きが低くなっています。
図1 半導体プロセッサの性能向上トレンド
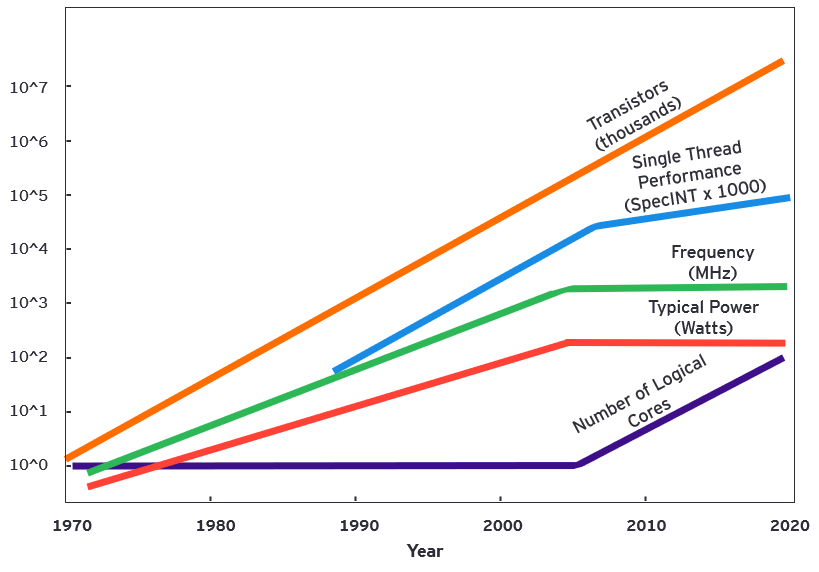
出所:各種業界記事を元にEYが作成
微細化して(すなわち、小さくして)高性能化を図ることができないのであれば大きくして高性能化を図るというのが、半導体業界の選択したソリューションです。「チップレットアーキテクチャ」や「2.5次元・3次元実装」などさまざまな呼び方があるものの、共通するのはいずれも複数のチップをつなぎ合わせて1つの半導体プロセッサを作る技術になります。
これにより、1つのチップに機能を搭載した半導体(monolithic、モノリシック)よりも広い面積をもつ半導体プロセッサを作ることができるようになります。その結果、広い面積で放熱が可能となって発熱量の制約が緩和され、その結果演算性能を向上させることができるようになります。
一方でこの方法のデメリットは、基板上の周辺回路や冷却システム、電源モジュールなども高性能化・大型化する必要があり、システム全体が大きくなることです。一般的なサーバーは標準規格の19インチ幅のラックに実装されるため、サーバーの大型化は高さ方向に延びていくことになり、さらに冷却強化のためにラック内のサーバーの上下間隔を空ける必要が出てきます。結果的に1つのラックに搭載できるサーバー台数が減ることになるため、同じ台数のサーバーを設置するにはより多くのラック数が必要になります。
つまり、半導体の微細化技術の鈍化が半導体チップ面積の大型化につながり、それを実装するためのコンピュータシステムが大型化することになります。
なお、これら消費電力の急増と放熱課題に対して、液体冷却技術の進歩と実装が進んでおり、最近では、液浸(文字通りデバイスを液体に浸す冷却方式)の導入も進み、設備の高度化や大規模化が進行していますが、放熱課題に関する最新のトレンドフォローと解説は、別の機会に紹介します。
Ⅲ 並列コンピューティング技術の進化
第Ⅲ章では、並列演算の活用によるコンピューティングのブレークスルーがAIモデルの大型化につながっていることを説明します。
半導体の性能鈍化への対策として半導体プロセッサに複数の演算コアを搭載するマルチコア化が進み始めました。<図1>の一番下の折れ線は半導体プロセッサに搭載される演算コア数を示しており、2005年ころからマルチコア化が始まっています。
ここまで半導体プロセッサとしては、PCなどを駆動する中央演算装置(CPU: Central Processing Unit)が主役でした。しかし、CPUはプログラムの最初から最後まで順番に演算していく逐次演算処理に適しているため、マルチコア化による並列演算のメリットをあまり出すことができません。また、コア数を増やすと熱密度が高まってしまうため、CPUのマルチコア化は大きく進まず、<図2>のように現在のコンシューマPC向けでは2コア~16コア止まり、業務量を集約して効率を上げられるサーバー用途でも最大128コアとなっています。
一方、画像処理専用の半導体プロセッサとして開発されたGPU (Graphic Processing Unit)は、最初から並列演算を前提に設計されています。1枚の画面を複数に分割し、それぞれ平行して演算処理を行い、最後にまた1枚の画面に合成することで画像処理を高速化できます。これを画像処理だけではなく汎用(はんよう)的な演算処理に使うGPGPU (General Purpose GPU)が2006年ころから広がり始めます。
CPUのコアは分岐命令など高度な演算に対応するため複雑で大きくなりますが、GPUのコアは、四則演算など比較的単純な演算のためシンプルで小さくできます。このため<図2>のようにコンシューマー向けGPUで1万8,176コア、データセンター向けGPUで2万480コアとなっており、GPUの方がコア数ではCPUを圧倒しています。
図2 CPUとGPUのコア数の比較
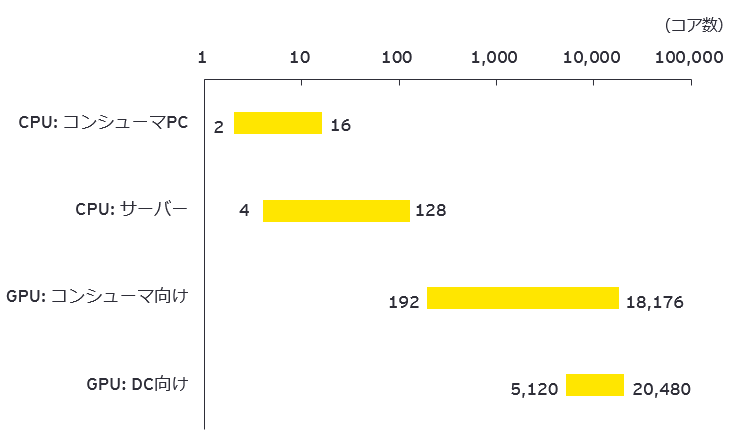
出所:各社公表資料よりEY作成
GPGPUの登場によって並列プログラミングの難易度が下がり、さまざま並列演算ソリューションが開発されます。その代表的なものが機械学習であり、特にニューラルネットワークを模したディープラーニングの実用化がAI開発の加速につながっています。
AI研究者の業界団体Epoch AIが集計しているAIモデルのデータによると、<図3>のように2010年までの約50年間は年率1.4倍の規模で大きくなっていたAIモデルは、2010年以降は年率4.1倍のペースで大きくなっています。Epoch AIでは2010年以降をディープラーニングの時代(Deep Learning Era)と表現しています。
また、生成AIの性能の1つとなる学習時のパラメータ数は、2018年に発表された生成AIが1億個だったのに対し、2020年には1,750億個、2022年には3,500億個、2024年には1兆個を超えたと推測されています。
このようなAIモデルの大型化に対応すべく、データセンター向けのGPUを搭載したサーバーを多数連結し、あたかも1台のGPUとして利用することが可能な技術も進化しています。現在の最先端では1台当たり2万480コアのGPUサーバーを576台連結して1,179万コアの巨大なGPUとして使うことが可能です。
総括すると、第Ⅱ章で説明した半導体の微細化技術の鈍化によるシステムの大型化と、AIモデルの大型化によるシステムの大型化が組み合わさり、コンピュータシステムは大規模化のトレンドの中心にあります。
図3 AIモデルの規模はディープラーニングを境に年率4.1倍に加速
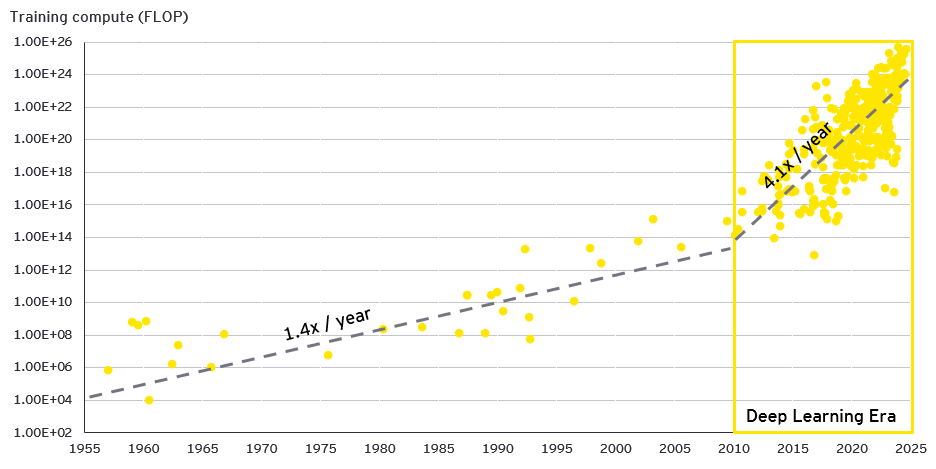
出所: Epoch AIよりEY作成。Epoch AI, ‘Data on Notable AI Models’. Published online at epochai.org. Retrieved from ‘epochai.org/data/notable-ai-models’ [online resource]. Accessed 1 Aug 2024.
Ⅳ 生成AIによる高性能コンピューティングの民主化
第Ⅱ章と第Ⅲ章では供給側の技術の観点からコンピュータシステムの大型化を説明しました。本章では需要側の技術変化の観点から需要の拡大を説明します。
従来のAIを使いこなすにはPythonやR、Juliaなど専門的なプログラミングの知識が必要です。生成AIもこれらのプログラミング言語を用いて開発されています。
一方、生成AIを使う観点からはプログラミングの知識は不要で、コマンドプロンプトではなく自然言語のプロンプトによって誰でも使うことができます。このため生成AIの利用のハードルは著しく低下し、利用者数の急増をもたらしています。2022年11月に公開された生成AIはその後1カ月ほどの間に利用者数が1億人を超えたと言われており、SNSなどの人気アプリケーションですら数年かかる水準にごく短期間で達したことになります。
スパコンなどの高性能コンピューターを一般ユーザーが使うことは無く、科学技術計算や創薬開発、天気予報などを通じて間接的にその恩恵を享受するにとどまります。しかし、生成AIはスパコン並みの高性能コンピューターを一般ユーザーが直接的に使うことができます。生成AIによって高性能コンピューターを誰でも使えるようになったことは、高性能コンピューティングの民主化と言っても過言ではないでしょう。
この民主化の結果、並列演算による高性能コンピューティング資源を、万人単位の専門家ユーザー向けではなく、億人単位の一般ユーザー向けに提供する必要が生まれています。データセンターの建設ラッシュはこのような構造的な変化を背景としており、その勢いは当面の間収まることはなさそうです。
Ⅴ おわりに
ここまで、半導体の微細化技術の鈍化によるシステムの大型化、並列コンピューティング技術の進化によるAIモデルの大型化、これらを土台とした生成AIによる高性能コンピューティングの民主化が起こっていることを示しました。これらの構造的な変化を背景としているためAIブームは一過性の現象にとどまらない可能性があり、それを支えるために継続的にデータセンターインフラの拡大が必要となるでしょう。
本稿が皆さまのデータセンター需要に対する理解を深める一助となれば幸いです。
サマリー
半導体の微細化技術はムーアの法則に従って進化してきましたが、2010年ころを境に微細化ペースの鈍化が顕著になっています。この技術の制約と、その制約を乗り越えるコンピューティング技術の進化が昨今のデータセンター需要拡大をけん引しています。本稿ではそれらの関係性を明らかにします。
関連コンテンツのご紹介
戦略(EYパルテノン)、買収・合併(統合)・セパレーション、パフォーマンスの再構築、コーポレート・ファイナンスに関連した経営課題を独自のソリューションを活用し、企業成長を支援します。
全国に拠点を持ち、日本最大規模の人員を擁する監査法人が、監査および保証業務をはじめ、各種財務関連アドバイザリーサービスなどを提供しています。
情報センサー
EYのプロフェッショナルが、国内外の会計、税務、アドバイザリーなど企業の経営や実務に役立つトピックを解説します。
